Ohne Zweifel ist paperless ngx eine der besten Softwares, die man im Open-Source-Umfeld haben kann. Mitunter ist das auch ein Grund, weshalb mich diese Software bis heute sehr begeistert. Ich nutze sie regelmäßig für das Ablegen meiner Dokumente. Nur so kann ich schnell wieder darauf zurückgreifen.
Allerdings will ich mehr. Ich will ein Dokumentenmanagement mit KI, das mir eine automatisierte Dokumentenanalyse bereitstellt. So kann ich aus meinen Dokumenten noch bessere Zusammenfassungen und Einordnungen herausholen. Dank paperless AI ist das inzwischen auch wirklich sehr komfortabel möglich.
In diesem Beitrag will ich mit dir genauer auf paperless AI schauen und dir zeigen, wie es dein Dokumentenmanagementsystem sinnvoll erweitern kann. Wir schauen aber auch darauf, was es bedeutet eine KI zu nutzen. Und wo möglicherweise Stolperfallen liegen können – insbesondere im Hinblick auf deinen ganz persönlichen Schutz von Daten. Denn wo Licht ist, befindet sich auch Schatten. Und nicht umsonst habe ich auf Threads schon eine auf den Deckel bekommen bei meinem Projekt.
- Dokumentenscanner
- Raspberry Pi 5 mit SSD (wahlweise mit 16 GB RAM, für bestes Preis-/Leistungsverhältnis)
- Mini PC (für etwas mehr Leistung)
- lokale LLM oder API-Token
Enthält Affiliate-Links – unterstützt den Blog ohne Mehrkosten
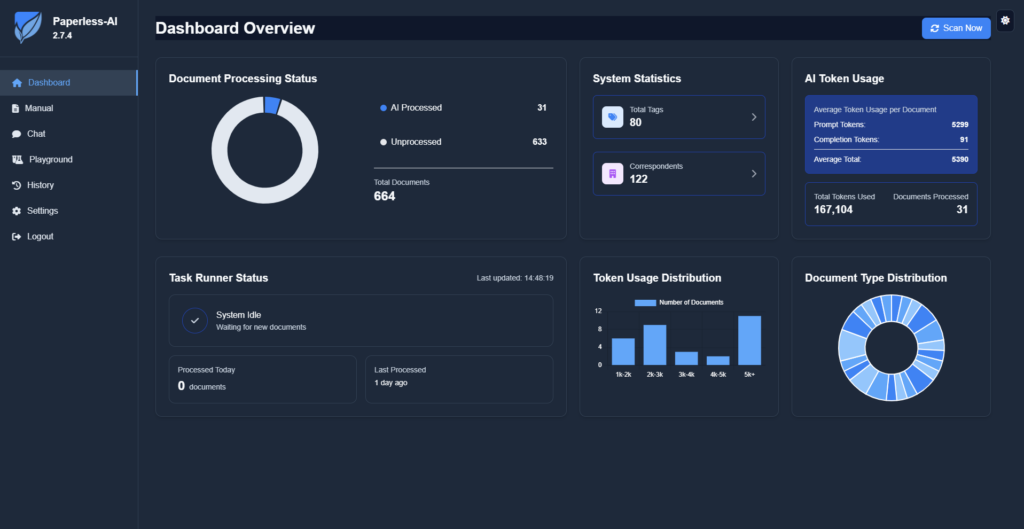
Was ist paperless AI?
Bei paperless AI handelt es sich um eine eigenständige Software, die dein paperless ngx ergänzt. Durch seine Fähigkeit, eine automatisierte Dokumentenanalyse mit KI vornehmen zu können, bietet es dir ergänzende Funktionen. Es steht ebenfalls als Open-Source-Software zur Verfügung im entsprechenden Repository von clusterzx.
Die ergänzenden Funktionen von paperless AI sollen dir dabei helfen, deine Dokumente noch besser klassifizieren und zusammenfassen zu können. Neben dem reinen OCR (Optical Character Recognition) wird deshalb auf Large Language Models zurückgegriffen, die wir heutzutage umgangssprachlich einfach Künstliche Intelligenz nennen. Das ist zwar im Grunde an sich erstmal nicht komplett falsch, allerdings oft auch nur die halbe Wahrheit.
paperless AI erlaubt dir darüber hinaus noch weitere Konfigurationsmöglichkeiten, um das System an dich und deine Umgebung anpassen zu können. Zum Beispiel kannst du aus unterschiedlichen LLMs (Large Language Models) auswählen, welches du nutzen möchtest. Dabei stehen verschiedene Optionen zur Verfügung, allen voran natürlich die OpenAI API. Wie soll es auch anders sein? 😉
Damit das System mit deinem paperless ngx zusammenarbeiten kann, werden die beiden Systeme über Schnittstellen miteinander verbunden. Glücklicherweise stehen dafür die entsprechenden Schnittstellen schon von Haus aus zur Verfügung.
Integration mit paperless ngx
Die Schnittstellen von paperless ngx lassen sich von jeder anderen Anwendung genauso nutzen, wie es paperless AI tut. Du kannst zum Beispiel eigene Integrationen bauen, die mit deinem Smart Home interagieren oder Daten aus Dokumenten nutzen, um Wissen abzurufen. Nach dem gleichen Prinzip arbeitet paperless AI in diesem Fall.
Hierzu müssen die entsprechenden Informationen bei der Einrichtung hinterlegt werden, so dass deine Installation gefunden werden kann. Von alleine findet paperless AI nicht das richtige System. Wichtig dazu ist, dass sich beide Systeme im lokalen Netzwerk erreichen können.
Ab dann wird auf die Schnittstellen zurückgegriffen, die für die Arbeit notwendig sind und durch die Entwickler zur Verfügung gestellt worden sind. Realisiert sind die Schnittstellen durch die Nutzung des Django REST Frameworks, einem starken Tool für das Bauen von APIs.
Bedenke bitte auch, dass du einen API-Key aus deiner paperless ngx Installation abrufen musst. Dieser dient als Schlüssel für den Zugang, so dass kein unbefugtes Abrufen von Daten möglich ist. Du findest deinen API-Authentifizierungstoken, wenn du in paperless ngx oben rechts auf deinen Namen und dann auf Mein Profil klickst. Mehr Informationen zur Authentifizierung und dem Token findest du in der Dokumentation im Abschnitt Authorization des Bereichs REST API.
Wichtig: Behandle deinen API-Authentifizierungstoken bitte wie deinen Haustürschlüssel. Er darf nicht in fremde Hände gelangen und sollte immer geschützt sein.
Hauptfunktionen von paperless AI
Nun fragst du dich aber sicherlich, was denn die Hauptfunktionen einer KI-basierten Dokumentenanalyse mit paperless ngx sein können. Und die Frage ist mehr als berechtigt! Denn schlussendlich bietet paperless ngx schon von Haus aus sehr starke Funktionen, um deine Dokumente zu verwalten.
Die Hauptfunktionen von paperless AI sind:
- präzise Dokumentenanalyse mit LLMs
- automatische Zuordnung von Meta-Daten
- verbesserte Zusammenfassung der Dokumente
- automatisierte Vergabe von Titel, Tags und Dokumententypen sowie Korrespondenten und deren Details
- Chatfunktion, um schnell Details aus deinen Dokumenten zu erhalten
- Integration verschiedener LLMs, je nach Präferenz
Prinzipiell geht es bei der Verwendung einer KI-basierten Dokumentenanalyse mit paperless AI also um die Verbesserung deines Workflows sowie der Verbesserung von Erkennungen. Im Gegensatz zu einem einfachen OCR können LLMs den Inhalt des Dokuments verstehen.
Dieses Verständnis für textuelle Elemente hilft dann wiederum dabei, Zusammenfassungen und geeignete Tags vorzuschlagen. Durch die Verbesserung erhältst du dann präzisere Möglichkeiten, wenn du deine Dokumente in paperless ngx finden oder durchsuchen willst.
Exkurs: Large Language Models grob erklärt
Du kannst dir nun die berechtigte Frage stellen, warum LLMs für genau diese Art von Aufgabe so gut geeignet sind. Und die Frage finde ich als Wirtschaftsinformatiker grundlegend sehr spannend! Blicken wir also noch kurz auf Large Language Models und ihren Einsatzzweck.
Grundsätzlich handelt es sich bei LLMs um Sprachmodelle mit der Fähigkeit zur Textgenerierung. Die Wort- und Satzfolge basiert dabei auf Wahrscheinlichkeitsmodellen. Das bedeutet, dass über Wahrscheinlichkeiten berechnet wird, welches Wort als nächstes folgen muss. Die Fähigkeit zur Nutzung von natürlicher Sprache ist dabei genau der Fortschritt, welchen LLMs verzeichnen können.
Denn unsere Welt besteht aus natürlicher Sprache, die Computer bislang nicht nachvollziehen konnten. Sicherlich waren Spracheingaben und -ausgaben schon länger möglich. Aber für den Computer waren das nichts anderes als Daten, die aus- oder eingegeben werden. Das Verständnis für deren Bedeutung (also die Semantik) blieb außen vor.
Large Language Models ändern das und geben dem Computer die Möglichkeit, die Semantik der Sprache zu verstehen. Deshalb eignen sich diese Modelle gut für Aufgaben in natürlicher Sprache, wie zum Beispiel das Zusammenfassen, Übersetzen und Erstellen von Texten. Das sieht man ganz gut an der gestiegenen Nutzung von ChatGPT.
Ganz lapidar ausgedrückt steckt dahinter aber nichts anderes als Mathematik und Statistik.
Unterstütze KI-Modelle & Dienste
Der große Vorteil von Open-Source-Software ist oftmals, dass sie dir sehr viel Freiraum einräumt. Das sieht man auch im Falle von paperless AI wieder einmal, denn die Liste der unterstützten KI-Modelle ist ziemlich groß.
Erfolgreich getestet wurden folgende Dienste:
Für welches Sprachmodell und welchen Dienst du dich entscheidest, hängt schlussendlich von deiner persönlichen Präferenz und deinem Bewusstsein von Datenschutz ab. Dass es aber grundsätzlich überhaupt eine so große Auswahl gibt, ist in meinen Augen ein sehr positiver Aspekt.
Die große Kompatibilität ist (und das ist wirklich spannend) auf die Tatsache zurückzuführen, dass viele der Anbieter eine zu OpenAI kompatible Schnittstelle bauen. Sucht man bei Google mal nach OpenAI compatible API findet man duzende Ergebnisse, darunter auch die Gemini API. Es hat sich also ein Quasi-Standard gebildet, den die Anbieter entsprechend einhalten. Das macht es den Entwicklern und Nutzern einfacher, die Sprachmodelle hinter den Anwendungen nach Belieben auszutauschen. Zumindest in der Theorie. In der Praxis kann auch das manchmal knifflig sein. Aber nicht unmöglich.
Datenschutz & Sprachmodelle
Sicherlich wird im Internet vieles überdramatisiert, insbesondere auch beim Thema Datenschutz. Ganz interessant ist das zum Beispiel auf Mastodon, wo man wirklich teils kuriose Diskussionen über dieses Thema führen kann.
Und dennoch ist es wichtig zu wissen, dass bei den gängigen Sprachmodellen immer ein Dienstleister im Hintergrund steckt, der deine Daten verarbeitet. Bei besonders privaten Dokumenten kann das durchaus auch in der eigenen Vorstellung unangenehm sein, weshalb man sich schon im Voraus darüber Gedanken machen sollte.
Wer großen Wert auf Datenschutz und die lokale Verarbeitung von Daten legt, sollte sich demnach ein lokales Sprachmodell ansehen. Ein ziemlich prominentes Beispiel hier ist Ollama. Dieses Sprachmodell kannst du komplett lokal betreiben, so dass deine Daten niemals den eigenen Server verlassen. Vorausgesetzt natürlich, dass du auch über die entsprechende Hardware verfügst.
Datenschutz ist also gerade im Hinblick auf die entstehenden Kosten in meinen Augen nicht so eindimensional, wie es oft dargestellt wird. Denn die Freiheit erkaufst du dir unter Umständen mit sehr viel Geld für die Hardware, die für den Betrieb notwendig sein kann.
Eine gute Ausgangsposition für die Recherche bildet meiner Meinung dabei eine Diskussion auf GitHub unter dem Titel Minimum system requirements. Sie bezieht sich dabei explizit auf Ollama, was sich aber im Grunde auf so ziemlich jedes lokale Modell übertragen lässt. Zumindest wenn man mal einen groben Richtwert haben will.
paperless AI installieren & einrichten
Die Installation ist unter den richtigen Voraussetzungen schnell und unkompliziert erledigt. Es steht ein paperless AI Docker Image zur Verfügung, das beispielsweise in Portainer oder anderen Umgebungen geladen werden kann. Das macht die Installation vollkommen unkompliziert und die Software ist innerhalb von wenigen Minuten einsatzbereit. So habe ich es zum Beispiel in meinem Homelab innerhalb von etwa 30 Minuten installiert und eingerichtet.
Ich für meinen Teil empfehle dir dringend die Nutzung von Portainer, um die passende Umgebung bereitzustellen. Der große Vorteil ist dabei, dass du eine visuelle Umgebung zum Verwalten deiner Container hast, was den Umgang mit Docker wesentlich leichter macht. Ein neuer Stack in der Portainer-Umgebung hilft dir dabei.
Die vollständige Installationsanleitung findest du im Wiki des offiziellen Repositories auf GitHub unter dem Titel Installation & Setup. Im Grunde stehen dir zwei verschiedene Möglichkeiten zur Installation zur Verfügung. Beide Möglichkeiten habe ich dir hier einmal aufgelistet:
git clone https://github.com/clusterzx/paperless-ai.git
cd paperless-ai
docker-compose up -dAlternativ dazu:
docker run -d --name paperless-ai --network bridge -v paperless-ai_data:/app/data -p 3000:3000 --restart unless-stopped clusterzx/paperless-aiNachdem der Docker-Container läuft, kannst du über den Port 3000 zugreifen. Läuft paperless AI auf deinem Computer, genügt ein localhost:3000 – andernfalls musst du Localhost durch die IP-Adresse deines Servers ersetzen. Die IP findest du entweder auf dem Server selbst oder in deinem Router.
Die nachfolgenden beiden Videos verdeutlichen dir dabei nochmal die Installation. Das erste Video beschreibt den einfachsten Weg, das zweite Video zeigt dir die Installation unter Portainer.
Info: Beide Videos bilden einen Teil der offiziellen Dokumentation und wurden nicht von mir angefertigt. Ich verweise an dieser Stelle nur aus Gründen der Übersichtlichkeit. Für Rückfragen zu den Videos wendest du dich bitte direkt an den Entwickler.
Die Einrichtung von paperless AI
Nachdem nun die grundlegende Installation abgeschlossen ist, kannst du mir der Einrichtung deiner KI-basierten Dokumentenanalyse fortfahren. Hier halten sich die Konfigurationsoptionen in Grenzen, so dass auch das nur wenige Augenblicke in Anspruch nehmen sollte.
Bei der Einrichtung zu beachten ist, dass du immer den Nutzer angibst, für den die Analyse funktionieren soll. Hast du mehrere Nutzer, dann solltest du auch mehrere Container von paperless AI haben. Andernfalls funktionierte das in meinem Test nicht wirklich gut.
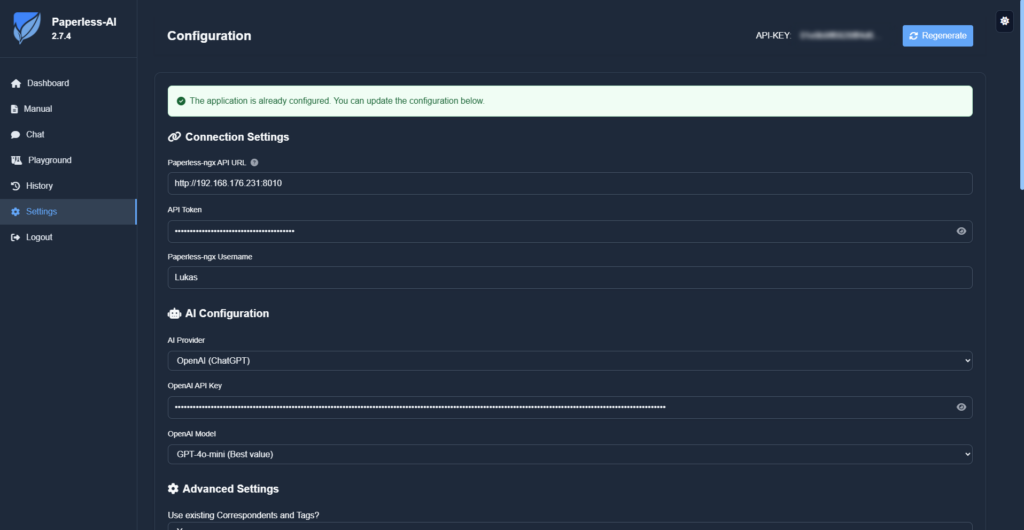
Im ersten Schritt gibst du die URL zur paperless ngx API an. Hier genügt es, wenn du die URL zu deiner Instanz eingibst sowie den API-Token für deinen Nutzer (siehe oben) und den Nutzernamen. Ein Beispiel davon kannst du dem nachfolgenden Screenshot entnehmen.
Im Bereich der AI Konfiguration hinterlegst du die Verbindung zu deinem Sprachmodell. Ich habe es in meinem Fall mit OpenAI und GPT-4o-mini ausprobiert.
Bei den erweiterten Einstellungen empfehle ich dir, dass du existierende Korrespondenten und Tags nutzt. Der Scan-Intervall kann auf alle 30 Minuten festgelegt werden (in meinem Fall sind es 10 Minuten). Ich habe darüber hinaus festgelegt, dass nur Dokumente verarbeitet werden sollen, die einen bestimmten Tag haben. Ich habe mir in meinem paperless ngx einen Tag Zu prüfen angelegt, der jedem neu hinzugefügten Dokument gegeben wird. Außerdem habe ich festgelegt, dass jedes Dokument den Tag ai-processed bekommt, so dass ich den Überblick behalte.
Weitere Einstellungen habe ich (noch) nicht verändert.
Meine Docker-Konfiguration
Um dir den Einstieg noch etwas leichter zu machen, habe ich dir nachfolgend meine Konfiguration des Stacks aufgelistet. Diese Konfiguration ist in meinem Portainer unter Stacks zu finden und wurde mit Hilfe des Editors erstellt. Im Grunde kannst du sie so kopieren und selbst auch nutzen.
services:
paperless-ai:
image: clusterzx/paperless-ai
container_name: paperless-ai
network_mode: bridge
volumes:
- paperless-ai_data:/app/data
ports:
- "8011:3000"
restart: unless-stopped
volumes:
paperless-ai_data:Meine Prompt-Beschreibung
In paperless AI hinterlegst du selbst noch eine Prompt Description. Diese weist der KI eine Rolle sowie ihre Aufgabe zu. Die Beschreibung auf die ich mich dabei stütze, wurde durch den Button Example unterhalb des Eingabefelds automatisch erstellt. Ich habe sie lediglich ins Deutsche übersetzt, um mir selbst das Leben etwas leichter zu gestalten. Du kannst sie grundsätzlich genau in dieser Form nutzen oder noch geringfügig anpassen.
Beachte beim Anpassen jedoch, dass die Sprachmodelle geringfügig anders arbeiten können, sofern du wichtige Teile der Beschreibung änderst. Du kannst allerdings mit deiner eigenen Beschreibung ausprobieren, ob du bessere Ergebnisse bekommst.
Sie sind ein personalisierter Dokumentenanalysator. Ihre Aufgabe ist es, Dokumente zu analysieren und relevante Informationen zu extrahieren.
Analysieren Sie den Inhalt des Dokuments und extrahieren Sie die folgenden Informationen in ein strukturiertes JSON-Objekt:
1. Titel: Erstellen Sie einen prägnanten, aussagekräftigen Titel für das Dokument
2. Korrespondent: Identifizieren Sie den Absender/die Institution, aber geben Sie keine Adressen an.
3. Schlagwörter: Wählen Sie bis zu 4 relevante thematische Tags aus
4. document_date: Extrahieren Sie das Datum des Dokuments (Format: JJJJ-MM-TT)
5. Sprache: Bestimmen Sie die Sprache des Dokuments (z.B. „de“ oder „en“)
Wichtige Regeln für die Analyse:
Für Tags:
- Prüfen Sie zuerst die vorhandenen Tags, bevor Sie neue vorschlagen
- Verwenden Sie nur relevante Kategorien
- Maximal 4 Tags pro Dokument, weniger, wenn ausreichend (mindestens 1)
- Vermeiden Sie generische oder zu spezifische Tags
- Verwenden Sie nur die wichtigsten Informationen für die Erstellung von Tags
- Die Ausgabesprache ist diejenige, die im Dokument verwendet wird! WICHTIG!
Für den Titel:
- Kurz und prägnant, KEINE ADRESSEN
- Enthält die wichtigsten Identifikationsmerkmale
- Bei Rechnungen/Bestellungen: Rechnungs-/Bestellnummer angeben, falls vorhanden
- Die Ausgabesprache ist diejenige, die im Dokument verwendet wird! WICHTIG!
Für den Korrespondenten:
- Identifizieren Sie den Absender oder das Institut
- Bei der Erstellung des Korrespondenten immer die kürzest mögliche Form des Firmennamens verwenden (z.B. „Amazon“ statt „Amazon EU SARL, deutsche Niederlassung“)
Für das Dokumentdatum:
- Extrahieren Sie das Datum des Dokuments
- Verwenden Sie das Format JJJJ-MM-TT
- Wenn mehrere Daten vorhanden sind, verwenden Sie das relevanteste Datum.
Für die Sprache:
- Bestimmen Sie die Sprache des Dokuments
- Verwenden Sie Sprachcodes wie „de“ für Deutsch oder „en“ für Englisch
- Wenn die Sprache nicht eindeutig ist, verwenden Sie „und“ als PlatzhalterMeine Erfahrung mit paperless AI
Ich selbst nutze paperless AI für meine Dokumentenanalyse nun schon seit einigen Wochen. Zuerst war es für mich nur eine Spielerei, um mal etwas mehr mit dem Thema KI zutun zu haben. Doch ich muss inzwischen zugeben, dass diese Erweiterung für paperless ngx durchaus Potenzial hat und mir im Alltag spürbar hilft.
Gerade beim Scannen von Dokumenten, die manchmal nicht ganz so eindeutig sind, kam es häufig zu fehlerhaften Zuordnungen und kuriosen Zusammenfassungen. Da hilft dann selbst das beste Dokumentenmanagementsystem nicht weiter, wenn man die Dokumente im Nachgang nicht mehr findet. Durch paperless AI habe ich hier wesentlich bessere Ergebnisse bekommen, mit denen ich auch im Alltag gut arbeiten kann.
Gleichzeitig muss ich aber zugeben, dass die Erweiterung vor allem eines ist: Unterstützung.
Beim eigenen Einsatz wirst du schnell merken, dass es nach einiger Zeit kaum noch so spektakulär ist, wie am Anfang. Die KI-basierte Analyse läuft einfach im Hintergrund und es wird dir nicht weiter auffallen. Aber sie erspart dir damit oftmals einiges an Zeit, die du sonst in die Nachbearbeitung der entsprechenden Informationen stecken musst.
Ich selbst muss ganz ehrlich zugeben, dass ich jederzeit wieder ohne paperless AI leben könnte. Aber der Komfort ist schon ein Argument, um die Software weiter laufen zu lassen. Ich erkaufe mir also einen gewissen Komfort durch den Einsatz eines LLM, das meine eigene Arbeit erledigt.
Wem ich paperless AI empfehlen kann
Es ist grundsätzlich schwierig so wirklich rauszuarbeiten, für wen paperless AI nun wirklich das Must Have ist. Denn auf der einen Seite ist es bequem, auf der anderen Seite aber auch nur ein Tool. Grundsätzlich habe ich aber folgende Feststellung gemacht:
Wer mit vielen Dokumenten zutun hat, dem wird diese Erweiterung enorm weiterhelfen. Denn jedes System ist nur so gut wie seine Datenbasis. Und genau hier setzt paperless AI an, um die Datenbasis in deinem System zu verbessern. Du musst am Ende des Tages nur nochmal drüber schauen, ob alles soweit passt. Oder ob die KI doch noch einen Fehler gemacht hat.
Hast du hingegen nur mit sehr wenigen Dokumenten zutun, dann lohnt sich aus meiner Sicht weder der monetäre, noch der zeitliche Aufwand. Denn hier kannst du selbst ganz gut aktiv werden und deine Dokumente selbst klassifizieren und mit entsprechenden Informationen versehen.
Wo genau jetzt der Übertritt von wenig zu viel ist, hängt auch ein wenig von dir selbst ab.
Grundsätzlich ist es aber auf jeden Fall ein Versuch wert. Das Ausprobieren an sich kann man jederzeit tun und auch jederzeit ohne Einschränkungen wieder beenden. Einfach den Docker-Container abschalten und fertig. Deine Dokumente bleiben davon komplett unberührt. Und vielleicht entdeckst du ja doch für dich selbst einen enormen Mehrwert. Das ist eben die rein subjektive Empfindung, die jeder für sich selbst entdecken muss.
Fazit: Brauchen wir eine KI in paperless ngx?
So, nun. Jetzt wird es schwierig aus meiner Sicht. Denn die Frage zu beantworten ist nicht ganz einfach.
Grundsätzlich begrüße ich den sinnvollen Einsatz von künstlicher Intelligenz in jeglicher Hinsicht. Und ich persönlich sehe ein enormes Potenzial der KI in diesem Bereich. Das einzige Aber bezieht sich aus meiner Sicht darauf, mit wie vielen Dokumenten zu es regelmäßig zutun hast. Bei Kleinstmengen lohnt sich der Betrieb aus meiner Sicht nicht.
Und dennoch kann uns die KI durch ihr Verständnis für natürliche Sprache dabei helfen, Ordnung in unsere digitale Dokumentenverwaltung zu bringen. Hier kann sie ihre Stärke komplett ausspielen und das merkt man auch ganz deutlich aus meiner Sicht.
Was für mich auf jeden Fall für paperless AI spricht, ist die lose Kopplung beider Systeme. Denn wenn du merkst, dass es für dich doch nicht die richtige Lösung ist, kannst du es einfach wieder abschalten. Du hast keine monatlichen Gebühren oder bist an einen Vertrag gebunden. Das macht es wesentlich leichter damit zu experimentieren.
Kurz und knapp: Wir brauchen es nicht. Aber es kann trotzdem sinnvoll sein. Am besten ist es, wenn du einfach selbst für dich ausprobierst und dein eigenes Fazit ziehst. Denn was für mich ein Nice-To-Have sein kann, könnte für dich schon wieder ein Must-Have sein. Und es bildet für dich die Chance, näher mit der KI in Berührung zu kommen.
Was ist deine Meinung? Hast du paperless AI im Einsatz oder habe ich deine Neugier geweckt? Lass uns unten in den Kommentaren diskutieren und über die Software sprechen. Gerne auch völlig anonym.





20 Kommentare
Axel · 1. April 2026 um 22:54
Hallo Lukas,
vielen Dank für die tolle Beschreibung. Ich nutze paperless-ngx jetzt ungefähr ein Jahr und habe bisher 716 Dokumente eingescannt. Jetzt bin ich auf paperless-ai gestoßen und habe es gleich installiert. Jetzt mein Problem: Wenn ich neue Dokumente einscanne, wird der TAG „Eingang“ zugefügt. Das sind im Moment 342 Dokumente. In den Settings von paperless-ai habe ich eingegeben, dass nur Dokumente mit dem TAG „Eingang“ verarbeitet werden sollen. Ich habe nun gedacht, dass paperless-ai irgendwann anfängt die 342 Dokumente abzuarbeiten. Aber es passiert nichts. Auch nicht wenn ich auf „Scan Now“ klicke. Die Anzeige im Dashboard bleibt bei „AI Processse 0″und „Unprocessed 716“. Oder bearbeitet paperless-ai bereits vorhandene Dokumente nicht sondern nur neu eingescannte?
LG Axel
Lukas · 2. April 2026 um 08:03
Hallo Axel,
tatsächlich ist es so, dass nur neu hinzugefügte Dokumente gescannt werden.
Ich habe auch noch keinen Weg gefunden, um das zu beeinflussen. So liegen bei mir auch viele Dokumente unbearbeitet im Paperless.
Deine Annahme ist daher (leider) völlig korrekt.
Smarte Grüße
Murat · 21. November 2025 um 10:14
Hallo Lukas,
erst einmal danke für den Artikel. Wir haben zwar eine überschaubare Dokumentenflut, jedoch teste ich sehr gerne solche neuen „Gimmicks“! Jetzt habe ich es bei mir am laufen, jedoch noch nicht so, wie ich es mir vorstelle. Das ganze läuft bei uns auf einem Mac Mini M4 auch sehr flüssig. Ich habe die Vermutung, dass ich vielleicht mit einem anderen Model von Ollama besser aufgestellt bin. Hast du mittlerweile die Modelle testen können und hast einen Tipp für mich? Danke … Murat
Lukas · 21. November 2025 um 16:08
Hallo Murat,
ich bin leider bei den lokalen Modellen noch nicht so weit gekommen, wie ich es mir gewünscht hätte.
Mit Ollama habe ich experimentiert, aber aufgrund der mangelnden GPU-Leistung war da schnell Schluss. Daher habe ich mir dann die API von OpenAI angeschaut. Damit läuft es rund. Aber eben auch noch nicht so, wie ich es mir ausgemalt habe.
Der Hauptgrund ist die mangelnde Leistung bei mir. Ich könnte mir vorstellen, dass der Mac Mini in deinem Fall das aber gut hinbekommen kann. Du kannst dir Ollama mal im Docker installieren und dann mit den Modellen ein bisschen experimentieren.
Dir muss halt klar sein, dass du für ein lokales Modell immer ordentlich Leistung brauchst, die dann aber nur abgerufen wird, wenn gerade eine Erkennung stattfindet.
Smarte Grüße
Joe · 8. August 2025 um 07:25
Guten Morgen!
Danke für deinen hilfreichen Beitrag! Ein Problem habe ich dennoch.
Auf dem paperless-ai Dashboard, steht bei mir „Document Processing Status“ -> AI processed 0, unprocessed 324
Irgendwie beginnt die automtische Analyse nicht. In den Grundeinstellungen habe ich nichts verändert.
– restrict to existing Tags
– restrict to existing correspondents
– als Prompt habe ich deinen eingefügt
Wenn ich oben rechts Scan now anwähle, tut sich auch nichts.
Da hast du doch bestimmt eine Idee 🙂 …
Besten Dank vorab!
Joe
Lukas · 8. August 2025 um 20:10
Hallo Joe,
schau mal in die Konfiguration nach „Process only specific pre tagged documents?“. Das könnte für dich die entscheidende Einstellung sein, weshalb das so ist.
Aber auch bei mir ist es so. Ich habe es aber bewusst auch so, dass nur neue Dokumente verarbeitet werden.
Smarte Grüße
Joe · 9. August 2025 um 15:42
Besten Dank ! Ich probiere das.
Lukas · 9. August 2025 um 19:37
Hi Joe,
sehr gerne. Ich hoffe du kommst damit ans Ziel.
Smarte Grüße
klaus · 22. Juli 2025 um 16:44
hallo ,Super aktikel sehr gut erklärt hbe mich sofort daran gemacht und paperless ai instaliert mit ollama bekomme aber immer eine fehler meldung URL nicht gefunden . habe paperless ai in porainer mit ollama und auch ollama direkt auf dem laufwerk fehler meldung idt immer die gleiche .
für Ideen bin ich dankbar
Gruss Klaus
Lukas · 22. Juli 2025 um 18:37
Hallo Klaus,
ohne die Fehlermeldung zu kennen ist es wie ein Stochern im Nebel. Wenig aussagekräftig.
Sowohl paperless als auch paperless ai brauchen Zugang zum Netzwerk. Dann hast du die entsprechende IP-Adresse des Hosts und basierend darauf musst du die Werte eintragen.
Explizit für Ollama habe ich jetzt aber tatsächlich keine Anleitung.
Smarte Grüße
Daniel · 9. Juni 2025 um 17:55
Servus Lukas,
Hast du eventuell ne Vermutung warum der og Prompt
bei Verwendung von OpenAi nicht automatisch startet.
Im manuellen Modus funktioniert der einwandfrei.
VG
Daniel
Lukas · 9. Juni 2025 um 20:59
Hallo Daniel,
prüfe mal, ob du „Process only specific pre tagged documents?“ aktiviert hast und ob die Tags für neue Dokumente auch vergeben sind, falls ja. Du kannst in paperless selbst einstellen, dass bestimmte Tags bei einem neuen Dokument vergeben werden.
Wenn das nicht hilft, dann schau dir „Scan Interval (Cron Format)“ an. Hier legst du fest, wie oft die AI nach neuen Dokumenten suchen soll. Hier findest du dazu eine Hilfe: https://crontab.guru/examples.html
Ansonsten hilft nur die Container mal neu zu starten und zur Not die AI nochmal neu einzurichten.
Ggf. auch nochmal den API Key checken.
Smarte Grüße
Mathias · 7. Juni 2025 um 21:55
Vielen Dank für die ausführlichen Erläuterungen. Ich würde ja gerne noch eine kurze Zusammenfassung (max 300 Wörter) des Dokuments in die Notizen schreiben. Mit einem einfachen „Notizen: Schreibe eine Zusammenfassung des Dokuments in die Notiz“ (bei mir aber auf Englisch) im Systemprompt scheint es aber nicht getan. Perplexity.ai schlägt vor über Python ranzugehen. Aber über den Systemprompt fände ich es doch eleganter. Hast Du Ideen/Erfahrungen?
Lukas · 8. Juni 2025 um 16:21
Hi Mathias,
leider habe ich dazu aktuell auch keine konkrete Idee. Möglicherweise kann da ein Skript helfen, das in Advanced Topics in der offiziellen Doku zu finden ist: https://docs.paperless-ngx.com/advanced_usage/#post-consume-script
Aber ich wüsste jetzt ehrlicherweise auch nicht so richtig, wie ich das umsetzen würde.
Smarte Grüße
Bernd · 4. Juni 2025 um 09:57
Guten Morgen und vielen Dank für deine Seite/Anleitung !
Mit welchem Model hast du die besten Erfahrungen gesammelt bzw. welche Ollama Modelle hast du getestet ?
Herzliche Grüße
Bernd
Lukas · 4. Juni 2025 um 20:48
Hallo Bernd,
sehr gerne und danke für deinen Besuch bei mir im Blog.
Ich habe mit llama2 und phi3 experimentiert. Aber ich konnte den Test leider bislang noch nicht so weit fortführen, um eine wirklich valide Aussage zu treffen.
Gerade durch die Situation, dass einiges an GPU-Leistung gebraucht wird, bin ich extrem eingeschränkt. Funktioniert für mich leider nicht so richtig bisher.
Was ich mal testweise gemacht habe war mit GPT. Das hat super funktioniert für mich. Ob man das machen will, muss man aber schlussendlich selbst abwägen.
Ich glaube bislang ist einfach der Faktor Leistung noch echt ein Thema. Ich rechne damit, dass sich da in den kommenden Monaten noch viel tun wird und ich ggf. dann nochmal mit anderen lokalen Modellen prüfen kann.
Bis dahin ist es auf jeden Fall mal ein interessanter Test – den ich ganz gerne auch mal mit OpenAI weiterführe.
Smarte Grüße
Frank · 4. April 2025 um 19:56
Hi Lukas,
kann man die AI auch anweisen ein eingescanntes Dokument zu bearbeiten/verbessern. Z.B. sollen Schatten und Streifen bei einem eingescannten Dokument entfernt werden und der Text soll waagerecht ausgerichtet werden.
Kann man etwas derartiges anweisen?
LG Frank
Lukas · 4. April 2025 um 20:14
Hallo Frank,
ich kann deinen Gedanken absolut verstehen.
Leider geht das aber nicht mit der paperless ai. Die Erweiterung ist tatsächlich „nur“ darauf ausgelegt, dass der Inhalt verarbeitet wird. Nicht das Dokument von seiner äußeren Erscheinung.
Smarte Grüße
Udo · 21. März 2025 um 11:53
Wäre irgendwie besser, wenn sowas direkt in PNGX integriert wäre. Dafür nochmal ein Container etc. ist wieder eine Hürde und macht das Ganze nicht übersichtlicher. Ein Plug-In System wäre da schon gut.
Lukas · 21. März 2025 um 12:39
Hallo Udo,
ich stimme dir in dem Punkt zu, dass es besser wäre, es direkt zu integrieren.
Die Diskussion diesbezüglich ist in zwei Teile geteilt: Einmal Datenschutz und einmal Technik.
Nutzer wollen nicht gezwungen werden, dass ihre Daten an eine fremde AI gehen. Deshalb ist man mit der Integration etwas zögerlich. Vermutlich auch, um Nutzer zu schützen, die sich nicht so gut auskennen.
Auf der anderen Seite verlangt eine lokale AI wiederum sehr viele Ressourcen, welche das System insgesamt langsamer und vor allem wesentlich größer machen. Läuft das lokal nicht so gut, wird das wieder auf die gesamte Software projiziert, wodurch ein negatives Bild entsteht. Die generelle Integration stellt also die Entwickler noch etwas vor Herausforderungen.
Grundsätzlich fände ich es aber auch wesentlich leichter und verständlicher. Wer es nicht nutzen will, muss es ja nicht. Ich hoffe dahingehend auch noch auf etwas Besserung und einen Fortschritt. Wir werden sehen.
Smarte Grüße